First of all, I would like to say thank you for designing such an amazing product!
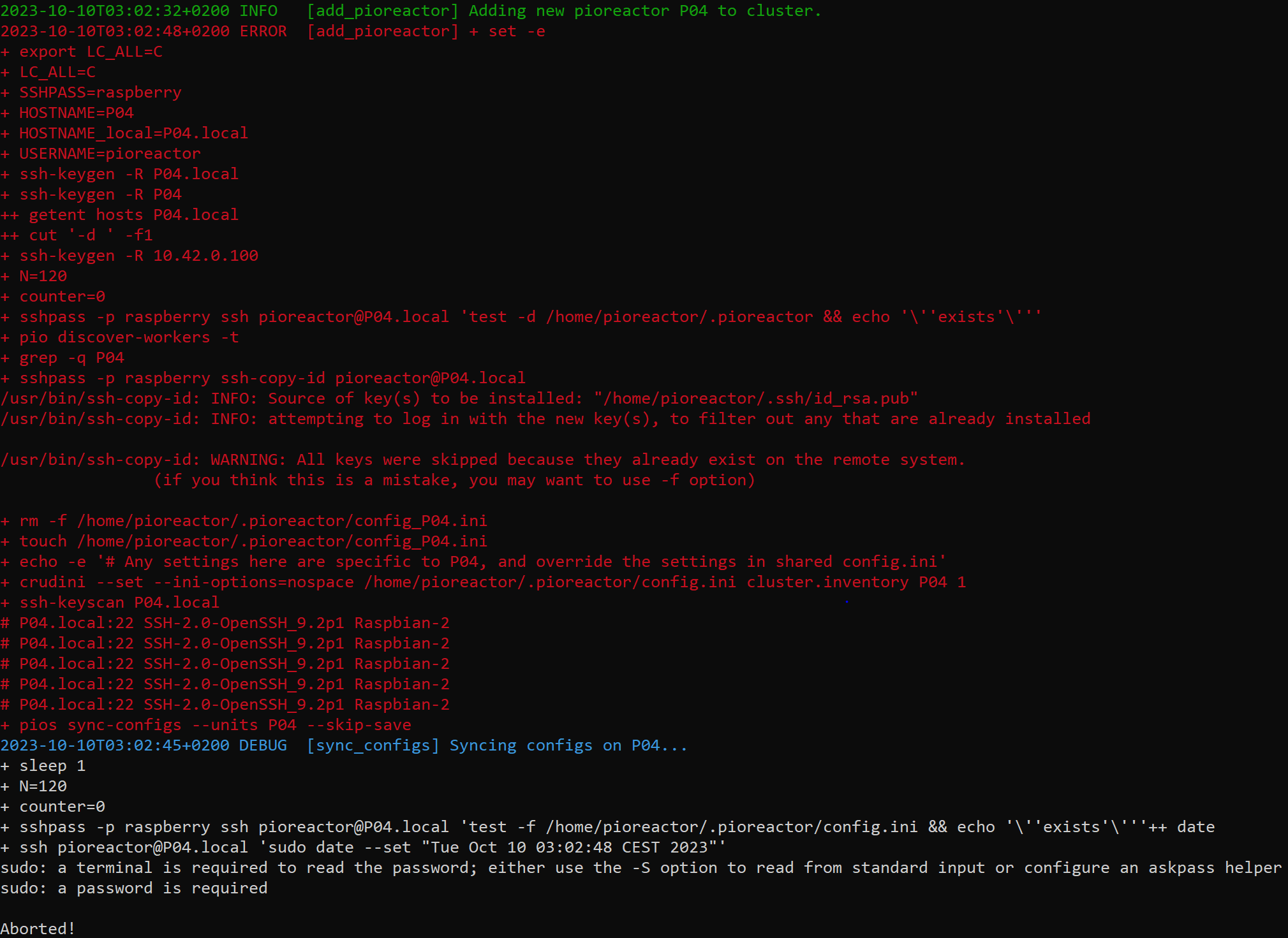
Unfortunately, I am having problem with adding the workers to my pioreactor cluster (leader: P01) and this is the output log I constantly receive for all the worker reactors (P04, P05, P06, P07, P08).
e[32m2024-01-11T16:05:24+0100 INFO [add_pioreactor] Adding new pioreactor P05 to cluster.e[0m e[31m2024-01-11T16:05:38+0100 ERROR [add_pioreactor] + set -e + export LC_ALL=C + LC_ALL=C + SSHPASS=raspberry + HOSTNAME=P05 + HOSTNAME_local=P05.local + USERNAME=pioreactor + ssh-keygen -R P05.local + ssh-keygen -R P05 ++ getent hosts P05.local ++ cut '-d ’ -f1 + ssh-keygen -R 192.168.100.196 + N=120 + counter=0 + sshpass -p raspberry ssh P05.local ‘test -d /home/pioreactor/.pioreactor && echo ‘'‘exists’'’’ + pio discover-workers -t + grep -q P05 + sshpass -p raspberry ssh-copy-id P05.local /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: “/home/pioreactor/.ssh/id_rsa.pub” /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: WARNING: All keys were skipped because they already exist on the remote system. (if you think this is a mistake, you may want to use -f option) + rm -f /home/pioreactor/.pioreactor/config_P05.ini + touch /home/pioreactor/.pioreactor/config_P05.ini + echo -e ‘# Any settings here are specific to P05, and override the settings in shared config.ini’ + crudini --set --ini-options=nospace /home/pioreactor/.pioreactor/config.ini cluster.inventory P05 1 + ssh-keyscan P05.local # P05.local:22 SSH-2.0-OpenSSH_9.2p1 Raspbian-2 # P05.local:22 SSH-2.0-OpenSSH_9.2p1 Raspbian-2 # P05.local:22 SSH-2.0-OpenSSH_9.2p1 Raspbian-2 # P05.local:22 SSH-2.0-OpenSSH_9.2p1 Raspbian-2 # P05.local:22 SSH-2.0-OpenSSH_9.2p1 Raspbian-2 + pios sync-configs --units P05 --skip-save e[36m2024-01-11T16:05:36+0100 DEBUG [sync_configs] Syncing configs on P05…e[0m + sleep 1 + N=120 + counter=0 + sshpass -p raspberry ssh P05.local ‘test -f /home/pioreactor/.pioreactor/config.ini && echo ‘'‘exists’'’’ ++ date + ssh P05.local ‘sudo date --set “Thu Jan 11 16:05:38 CET 2024”’ sudo: a terminal is required to read the password; either use the -S option to read from standard input or configure an askpass helper sudo: a password is required e[0m Aborted!
Despite the failure, I can see that the watchdog detected the workers and even though I receive the error, the workers appear in the cluster (sometimes) however they are just offline and do not give any blue light on the HAT even when manually tried.
Hm, maybe something changed in the latest software. I’ll check this hour. 1) Can you tell me which Raspberry Pi Imager you are using, and 2) if you downloaded the worker image very recently (like today or yesterday)?
Could be. I am used imager_1.8.4.exe and I downloaded worker image 2 days ago (10/02/2024). In the mean time, I will 1) reflash two of the reactors 2) download new worker image to see if makes any difference and update you the outcome
Okay I do not know what exactly happened, I did another power-cycle and the worker automatically added to the cluster even without searching for the reactor.
So, I will try to see 1) if asking to add reactor followed with a power-cycling adds other reactors with old worker image (from 10/01/2024) 2) if not, would replacing new worker image followed with power-cycling have the successful outcome.
So I tested an existing leader connecting to a freshly downloaded worker locally, and I was able to connect the two without issue. Hm hm hm.
The error you posted looks like it’s a permission problem on the worker. Are you comfortable with SSH? If you power on a worker that’s having trouble, you can SSH into it with ssh pioreactor@P05.local (for example, that’s worker P05), and enter “raspberry” as the password. Once on, try running something like sudo cat /etc/hostname - does that ask for a password?
Good feedback! I tried to add other reactors however I receive:
“Unable to complete installation. The following error occurred: Timed out, see logs.”
Hence, I will try to install new worker image (from 12/01/24) and try to see if that would make any difference.
Unfortunately, I do not have admin access to run “ssh” due to company restrictions. I actually wanted to do so, as it was suggested in the previous topics and guidelines. I asked for premission, however, it is not going be granted before Monday (15/01/2024).
Hence, in the upcoming days I can update the topic if I get more info from the ssh side.
This could be just that the worker isn’t “online” yet. I would try again in a moment. It can take a few minutes for the worker to get online.
Yes, I’ll keep investigating, too. The original error you are seeing happens late in the connection process, and a simple (manual) worker reboot should complete the process. Sorry about the difficulty!
Okay this makes sense, but it is still weird to get it for a reactor who has been connected to power for hours. I suspect, it might be due to corrupt SD card because it also does not get recognized by the watchdog. However, this might still be due to not being “online” so I will look to this and update if I get a different outcome.
I can understand why you would recommend SSH access. It would make it easier to resolve this through the command line interface.
This being said, it is my pleasure to learn this amazing product so no need to sorry. I am actually enjoying to go through the learning process!
Okay so neither 1) or 2) worked. However, I got access to the CLI and and after running what you suggested here:
It asked me enter password which was raspberry and after this I was able to gain access to the worker in the CLI.
Also, when I ran “pio discover-workers” when connected to the leader, I get the leader and all the workers listed (even the ones that are not added to the cluster).
However, when I ran “pio add-pioreactor” (again when connectde to the leader) I only get this error log:
2024-01-12T17:43:34+0100 ERROR [add_pioreactor] + set -e
sshpass -p raspberry ssh P04.local ‘test -d /home/pioreactor/.pioreactor && echo ‘'‘exists’'’’
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that a host key has just been changed.
The fingerprint for the ED25519 key sent by the remote host is
SHA256:hktL1D7D3a80ZORzc9jK/AHfogOLzS5vONqiGDhhJzU.
Please contact your system administrator.
Add correct host key in /home/pioreactor/.ssh/known_hosts to get rid of this message.
Offending ECDSA key in /home/pioreactor/.ssh/known_hosts:14
remove with:
ssh-keygen -f “/home/pioreactor/.ssh/known_hosts” -R “p04.local”
Host key for p04.local has changed and you have requested strict checking.
Host key verification failed.
++ date
echo ‘Connection to P04.local missed - Fri Jan 12 17:36:07 CET 2024’
Very strange. That warning shouldn’t appear. Are you using the built-in local-access-point network, or on your institutions network? (I’m guessing the latter since you needed SSH access).
What I think is going on is a network issue. You may be on a network type we haven’t seen before. Let me think more about this.
@sharknaro can you put me in contact with your IT team? My email is cam@pioreactor.com if you want to share their contact with me. I’d like to learn more about the network.
We are using a WIFI connection actually and my manager has successfully connected a leader and 2 workers to the WIFI network without problemface (plus the one reactor I connected after power-cycling).
After that we ordered more units and this problem happened when I tried to add them to the cluster.
The WIFI is setup by my manager which has contacted with you before, so the IT department might not be helpful in this case as they might not know the WIFI connection.
I will provide your contact adress to them and also share their contact address with you on Monday once I get premission from them
Thank you very much for all your help and time so far!
I came with more information, so I learned that we are using a SIM card as a WIFI Hotspot to connect the pioreactors, so it is not institution network and because of that the IT Team might not be helpful for the case.
I think you are right about the network issue, because I when I switched to built-in local-access-point, I was able to connect the workers to the leader/hotspot pioreactor.
Despite successful connection, the initial error log provided in my first post (shown below) was still illustrated before the reactors got added to the cluster, so perhaps the reason for this is unrelated with the network?
Ah okay that information helps. Still very strange you keep seeing that sudo error. I’m unable to reproduce it, too. Is it only worker P04 that has had this problem?
Give me some more time to think about it, and I’ll get back to you.
You can SSH into your workers (even if they are not connected to the cluster or show up in the UI - so long as they are on the same network). Can you log into one (that is having trouble), and try the following command:
sudo cat /etc/sudoers.d/010_pi-nopasswd
Do you get a a) prompted for a password? And b) what is the output of that command?